本文主要介绍多模态神经翻译的几个任务:
Image-pivoted Zero-resource Translation (Bilingual lexicon induction)
Unsupervised Bilingual Lexicon Induction from Mono-lingual Multimodal Data
双语词汇归纳是一项长期存在的自然语言处理任务。近年来的研究表明,在不依赖平行语料库的情况下,以图像为中心学习词汇归纳是一种很有前景的方法。然而,这些基于视觉的方法只是简单地将单词与整个图像关联起来,这就限制了翻译具体的单词,并且需要以对象为中心的图像。
当一个单词出现在一个句子的上下文中时,我们人类可以很好地理解单词。因此,在本文中,我们建议利用图像及其相关的字幕(caption)来解决以前方法的局限性。提出了一种使用不同单语多模态数据训练的多语多模态数据字幕模型,将不同语言的单词映射到联合空间。从多语言描述模型中归纳出两种类型的词表示:语言特征和局部视觉特征。语言特征是在具有视觉语义约束的句子语境中习得的,这有利于学习与视觉无关的词的翻译。局部化的视觉特征(localized visual feature)关注图像中与词相关的区域,从而减轻了图像对突出视觉表征(一张图片中只有一个单词表示的物体)的限制。
基于图片的零样本翻译任务的研究意义
现如今,机器翻译任务已经深入渗透在我们的日常生活中,“百度翻译”,“谷歌翻译”等API为我们的生活带来了许多便利条件。而这些表现优异的机器翻译模型背后,离不开海量的成对双语语料来支撑模型的训练。但是小语种的成对双语语料是十分匮乏的。在这种情况下,无监督翻译模型的设计显得尤为重要。
那么,在没有双语对照关系的数据储备下,机器该如何学到翻译知识呢?回想一下我们还是孩童时,是如何学习外语的。我想大部分人通常都躲不过看图识字这一阶段。即便我们不会英语,看到一张苹果的图片,并配上“apple”,我们也会知道这个单词是“苹果”的含义。因为我们默认有着这样的认知——描述同一幅图片的词语或句子往往表达着相似的语义含义,因此我们可以使用图片这样的多媒体资源作为媒介,学习到两种语言的对应关系。人是如此,机器亦然。我们可以将图片作为媒介,利用图片对应起两种语言的单词或句子,从而完成词语,甚至是句子的翻译任务。
但是这种做法会存在两点缺陷:
- 仅根据图片翻译词语,翻译模型只会对具有视觉意义的词语有很好的翻译能力,如
名词,形容词,而对于图片无法明确表示的词语,翻译质量则会很差。 - 这种方法只能使用包含单一目标词语的图片,而现实生活中的图片往往都是包含众多物体的复杂图片。
Approach
针对上述的两点缺陷,我们分别设计了两种词语特征表示——语言特征表示和局部视觉特征表示,用于之后的对应词语匹配。这两种特征表示的抽取均通过一个“代理”任务——多语言图片描述生成来实现。
使用
源语言和目标语言的(图片,内容描述)数据训练一个双语图片描述生成器,通过共享同一个图片编码器和描述生成器`来迫使不同语言的词语被嵌入到同一个隐含空间内,含义相近的词语特征向量距离更近,而含义相远的词语特征向量距离更远。得到的这一特征就是词语的语言特征表示。在这种情况下,模型学习到的词语特征并不限制与图片内容一一对应,而是可以从其共存的句子环境中学到所有词语的语言信息,其中就包含“a”这类非视觉性词语。为了不限制图片只包含单一物体,我们设计将图片的部分区域与词语相对应,而不是拿整张图片与词语对应。这就是词语的局部视觉特征表示。将图片通过卷积神经网络得到的以空间区域划分的图片特征依次输入到图片描述生成模型中,用生成相应词语的概率表示该词语与这一图片局部区域的匹配程度。根据匹配程度对这些区域图片特征做加权和,便得到了这一词语的一个局部视觉特征。当然,同一个词语所出现的图片有很多个。因此,最终每个词语都会对应一个局部视觉特征集合。
在获得这两种词语的特征表示(语言表示+局部视觉表示)后,便可以进行两种语言之间的词语翻译。将两个词语的语言特征向量的余弦相似度和局部视觉特征向量的余弦相似度之和作为这两个词语是否符合同一语义的分值,再以词汇表中与待翻译词匹配分值最高的词语作为翻译后的单词。

From Words to Sentences: A Progressive Learning Approach for Zero-resource Machine Translation with Visual Pivots
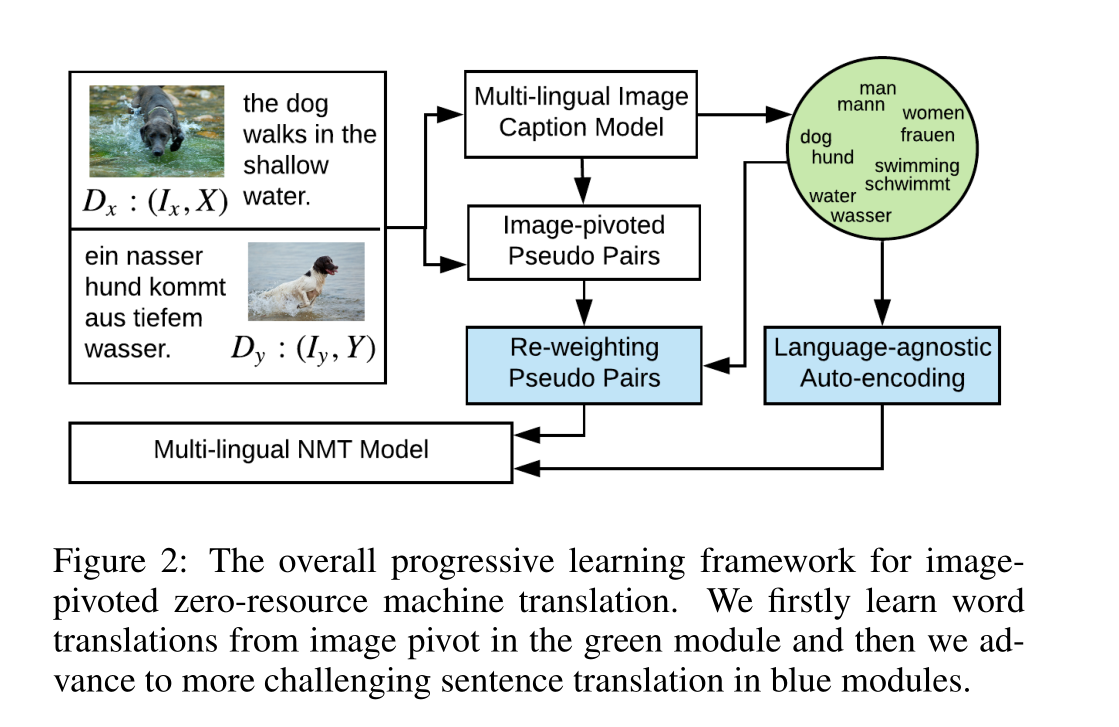
上一篇论文仅仅专注于词语翻译,那么这篇论文则专注于更复杂也更有研究需求的句子翻译。这篇文章的巧妙点在于利用预训练的多语言图片描述生成模型生成双语的图片内容描述,以此来作为成对数据训练机器翻译模型,从而解决数据匮乏的问题。当然,由于图片描述生成模型并不是完美的,而且“一图胜千言”,描述同一张图片的句子可能是很多样的。这样生成的训练数据往往存在很多噪声。因此,这篇论文着重研究并提出了两个降噪方案,来提升无监督机器翻译的质量。
Motivation
神经机器翻译模型缺乏大规模的并行语料库。相反,我们人类可以学习多语言翻译,即使没有平行文本,通过把我们的语言引用到外部世界。为了模拟人类的学习行为,我们以图像为中心,实现了零资源翻译学习。然而,一图胜千言,描述同一张图片的句子可能是很多样的,这样生成的训练数据往往存在很多噪声,从而阻碍了翻译模型的学习。However, since captions related to images are not necessarily good mutual translations, such learning approaches also suffer from noisy rewards.与图像相关的字幕不一定是很好的相互翻译。
在这项工作中,我们为基于图像的零资源机器翻译提出了一个渐进式的学习方法。由于基于图像的词的多样性较低,我们首先学习基于图像的词级翻译,然后利用学习得到的词级翻译来抑制以图像为中心的多语言句子中的噪声,进而学习句子级翻译。
第一种降噪方法
第一种是对有噪声的句子根据其噪声程度赋予不同的权重,使得有噪声的数据对翻译模型训练优化的影响较小,优质的训练数据对翻译模型优化的影响更大。主要做法是计算源语言和目标语言句子的最小EMD(Earth Mover’s Distance)距离。其中,词与词之间的距离用多语言图片描述生成模型中计算得到的词语嵌入特征向量的余弦距离来表示。由于这一预训练好的图片描述生成模型针对不同的语言共享图片编码器和描述生成器,因此不同语言的词语会被嵌入到同一个隐含空间中。在这一空间中,语义相近的词语的特征向量更近。根据句子层级和词语层级的EMD距离,便可以对损失函数中每个训练样例及每个样例中的词语的贡献度加以权重,从而减轻噪声对NMT模型性能的影响。
第二种降噪方法
第二种降噪方法是让NMT模型对“源语言的句子”进行重建。这里的“源语言的句子”实际是经过噪声化的句子。我们对句子随机进行词语调位、词语增添,词语丢弃等操作,训练NMT模型重建出原来完好的句子。这一自我编码解码的方式可以提高模型的鲁棒性。
最终的实验结果表明,通过以上两种降噪方式,可以很大程度上提高无监督机器翻译的质量。
Language Pivoted zero-source caption
既然图片等视觉信息可以对无监督的机器翻译任务提供很大帮助,那么反过来,机器翻译任务是否可以为计算机视觉相关任务,如图片描述自动生成带来帮助呢?答案是肯定的。
图片描述生成任务是对于给定的一张图片,自动生成描述图片内容的自然语言描述。这一任务从提出至今已有较长的研究历史,然而大部分工作都只专注于英文图片描述生成模型的研究。为了满足世界各地人们的需要,尤其是非母语为英语的人们,训练其他语种的图片描述生成模型十分必要。然而,由于用来训练图片描述生成模型的训练数据全部需要人工标注,为每一种语言,尤其是小语种标注大量的(图片,内容描述)数据几乎是不可能的。因此,我们希望可以利用已有的图片描述数据集来训练任一语言的图片描述生成模型,这也被称作跨语言图片描述生成。那么,如何在只了解一种语言的图片描述知识的情况下,自动为图片生成另一种语言的内容描述呢?或许机器翻译可以帮这个忙。
2018年,Jiuxiang Gu等人提出先在数据上训练这种语言的图片描述生成模型,随后通过机器翻译模型将所生成的描述翻译到目标语言。然而,由于机器翻译模型并不是完美的,在翻译的过程中,种种翻译错误严重影响了最终生成的描述质量。我们在Unpaired Cross-lingual Image Caption Generation with Self-Supervised Rewards这篇工作中总结了两种翻译错误,分别是语言表达不通顺和语义翻译不正确。前者会导致翻译得到的目标语言图片描述存在语法错误,后者则可能出现句子所描述的内容与图片不符的情况。针对这两种错误,我们设计了两种奖励函数来解决问题。下面,我们来详细了解这篇文章。
Unpaired Cross-lingual Image Caption Generation with Self-Supervised Rewards
这篇文章利用机器翻译对跨语言的图片描述生成任务进行了探索。讨论如何在某种语言的图片描述数据匮乏的情况下,训练该语言的图片描述生成模型。这对于除英语外的其他语种的图片描述生成模型的训练提供了思路。
我们以语言作为支点,使用资源充沛的英文数据来训练其他语言的图片描述生成模型。首先,通过机器翻译将英文的训练数据翻译到目标语言,随后以(图片,翻译得到的目标语言内容描述)作为训练数据来训练目标语言的图片描述生成模型。由于机器翻译模型并不完美,种种翻译错误使得这样的训练数据中存在很多噪声。我们分析总结了两种错误,分别是语言表达不通顺和语义翻译不正确。
Motivation
生成不同语言的图像描述对于满足全球用户的需求是至关重要的。然而,为每一种目标语言收集大规模的成对图像标题数据集是非常昂贵的,这对于训练下降图像描述模型至关重要。以往的工作都是通过一个主语言,借助主语言中的成对图像标题数据和pivot-to-target机器翻译模型,来解决跨语言图像标题的非成对问题。然而,这种以语言为中心的翻译方法存在着由中心到目标(pivot-to-target)的翻译带来的不准确性,包括不流畅性和视觉无关性错误。在本文中,我们提出在强化学习框架中生成具有自监督奖励的跨语言图像描述,以减少这两类的错误。我们利用目标语单语语料库的自监督来提供流畅性奖励,并提出了一个多层次的视觉语义匹配模型来提供句子级和概念级的视觉关联奖励。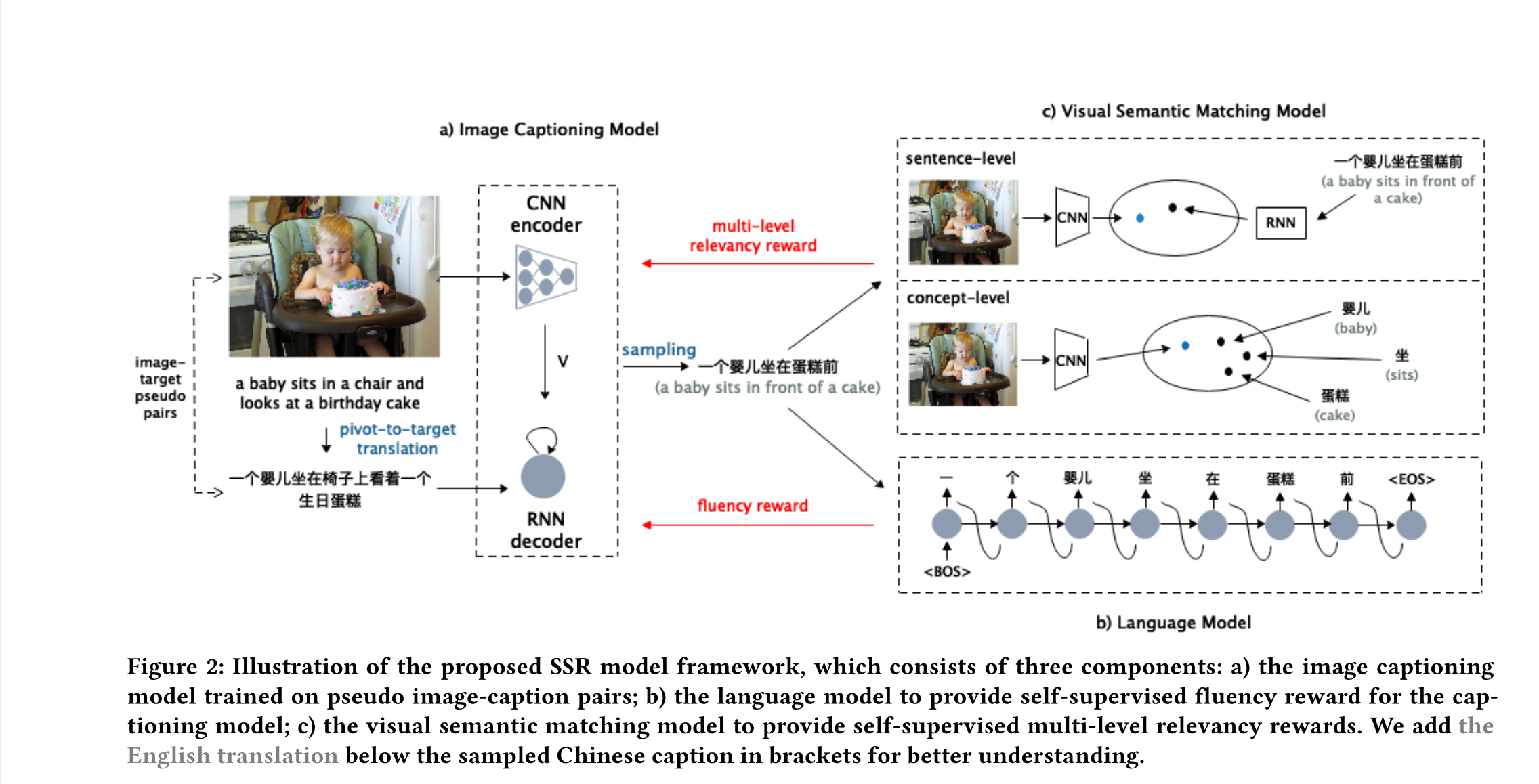
Multimodal Enhanced Translation
以上两个任务证明了跨模态信息对于数据匮乏情况下的无监督学习任务可以给予更多的指导信息,对无监督模型的训练效果有很大提升。那么,在数据充裕的情况下,如存在大量成对数据的机器翻译,跨模态信息的加入是否还能进一步提升模型质量呢?以下两篇论文就对这一问题进行了探索。
VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research
这篇论文通过收集并标注视频和中英文的视频内容描述数据,证明了在存在成对翻译数据的情况下,引入跨模态信息(这里是视频),会进一步提升机器翻译模型的质量。其中,跨模态信息的加入主要从以下两个方面对机器翻译带来更多增益。
消除歧义。我们都知道“一词多义”,在句子上下文信息不充裕的情况下,我们可能无法确定句子中某些词语的含义,自然更不能准确翻译到另一种语言。在这种情况下,视频信息便可以帮助消除语言上的歧义。
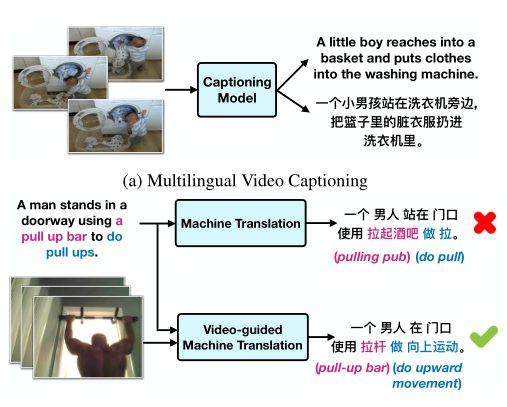
减小噪声。 在训练数据存在少量噪声时,跨模态信息的加入也会提供更多信息,增强模型的鲁棒性。
NAACL 2019的最佳短文this就着重对减少噪声方面跨模态信息的作用进行了实验和探索。它通过设计三种弱化源语言句子信息完整度的方法,探索跨模态信息对机器翻译模型的帮助会有多大。这三种加噪方式分别是隐藏句子中表示颜色的词语、隐藏实体词、逐级隐藏句子中的后$k$个词。实验证明,任一种方式下,多模态机器翻译模型都要明显优于纯文本的机器翻译模型,而且信息损失越严重,跨模态信息的作用越明显。这说明在训练数据复杂,存在噪声的情况下,跨模态信息的确会对机器翻译模型带来更多助益。
Bibtex
@article{caglayan2019probing,
title={Probing the Need for Visual Context in Multimodal Machine Translation},
author={Caglayan, Ozan and Madhyastha, Pranava and Specia, Lucia and Barrault, Lo{\"\i}c},
journal={arXiv preprint arXiv:1903.08678},
year={2019}
}


